
Podcast: Descargar (Duración: 33:37 — 31.7MB)
Ya hemos dedicado dos capítulos a temas relacionados con Ceph, por un lado Alta disponibilidad en Cluster de Proxmox con Ceph y por otro lado Ceph en Proxmox, pero no habíamos dedicado ningún capítulo específico para hacer de una Introducción a Ceph.
¿Qué es Ceph?
Lo primero será decir que Ceph es un sistema unificado que ofrece almacenamiento por bloques, por ficheros y por objetos.
- Almacenamiento por bloques con RBD (RADOS Block Device).
- Almacenamiento por ficheros con CephFS.
- Almacenamiento por objetos con RADOS Gateway (Compatible con S3).
RADOS significa Reliable Autonomous Distributed Object Store.
Los clientes establecerán las conexiones con los OSDs, lo cual también elimina cualquier punto único de cuello de botella.
- OSD: Object Storage Daemons
Y la distribución de la información se realiza mediante CRUSH que es un algoritmo para almacenar la información en el cluster, es decir, la información se almacena de forma ordenada gracias a este algoritmo, es totalmente predecible.
- CRUSH: Controlled Replication Under Scalable Hashing.
Es importante comentar que Ceph es un sistema SDS (Software Defined Storage)
¿Cómo funciona Ceph?
El punto central de Ceph es RADOS (Reliable Autonomous Distributed Object Store) y el nivel de RADOS consiste en el número de OSDs (Object Storage Daemons).
Cada OSD normalmente está mapeado a un único disco. Cada OSD es totalmente independiente y forma relaciones peer-to-peer para formar un cluster con otros OSDs.
Otro componente en un cluster de Ceph son los monitores, los cuales son los encargados de formar el consenso o quorum del cluster a través del uso de Paxos.
- Paxos es un algoritmo para el consenso distribuido, para formar el quorum.
Los monitores no están involucrados en la decisión de por donde va a ir la información y no tienen los mismos requisitos de rendimiento que los OSDs.
Los cluster maps se utilizan por los componentes del cluster de ceph para describir la topología del cluster.
Por último tenemos al manager que es el responsable de la configuración y las estadísticas.
Como ya hemos comentado el algoritmo encargado de situar los grupos dentro de los OSDs es CRUSH.
En último lugar tenemos a librados que es una librería de ceph que puede ser utilizada para construir aplicaciones que interactúen directamente con el cluster de RADOS para almacenar y recuperar objetos.
Discos
Hay que tener en cuenta que la elección de los discos adecuados es una decisión muy importante dentro de Ceph y no todos los discos son iguales.
Hay gente que considera que poner SSDs es suficiente, pero puede ser hasta contraproducente poner según qué discos SSD.
Por poner un ejemplo en discos SSD el bloque de flash normalmente es de 128k y aunque sólo queramos escribir 4 k en ellos el bloque entero tiene que ser leído y luego escrito, esto lleva mucho tiempo.
Los discos buenos tienen una memoria y un firmware que se encarga de estas tareas, por tanto nos podemos desentender, sin embargo los discos SSD de consumo domestico no hacen esto y es el procesador el que tiene que encargarse de esto, con lo que el rendimiento se viene abajo.
En cuanto a otros discos, tenemos que tener en cuenta que la limitación más grave no es el espacio, sino las IOPs (Input/Output Operations Per Second) del disco de un tamaño de 4k (es el estándar)
- Disco SATA 7200 RPM – 70-80 IOPS en escritura aleatoria
- Disco SATA 10000 RPM – 130 IOPS en escritura aleatoria
- Disco SCSI 7200 RPM – 80-95 IOPS en escritura aleatoria
- Disco SCSI 10000 RPM – 140-150 IOPS en escritura aleatoria
- Disco NEARLINE-SAS 7200 RPM – 100 IOPS en escritura aleatoria
- Disco SAS 10000 RPM – 140-160 IOPS en escritura aleatoria
- Disco SAS 15000 RPM – 180-200 IOPS en escritura aleatoria
- Disco SSD Primera gen – 8000 IOPS en escritura aleatoria
- Disco SSD Segunda gen – 50000 IOPS en escritura aleatoria
- Disco SSD Tercera gen – 120000 IOPS en escritura aleatoria
- Fusion IO Primera gen – 250000 IOPS en escritura aleatoria
- Fusion IO Segunda gen – 1200000 IOPS en escritura aleatoria
- Fusion IO Tercera gen – 9500000 IOPS en escritura aleatoria
Lista obtenida de Javierin.com, ahí tenéis más información sobre IOPS y discos muy interesante.
En el momento el que tengamos que diseñar un cluster es más importante conocer las IOPS que el espacio total, porque si podemso meter más discos a veces será siempre preferible meter más discos y no sólo por las IOPS.
Imaginad un cluster con 10 discos de 1TB donde uno falla con 500G de información, ahora tenemos que recolocar esos 500G entre los 9 discos restantes, si la red nos da 20MB/s tardaremos unos 45 minutos en hacerlo. Pero si el cluster fuera de 100 discos distribuir esos 500G entre 99 discos nos llevaría sólo 4 minutos a la misma velocidad de red. Como veis las IOPs son importantes, pero no lo único.
Memoria
Las recomendaciones de memoria son bastantes laxas, pero por lo general se establece que deberíamos de tener 3GB por cada OSD HDD y 5GB por cada OSD SSD, aunque realmente esto depende mucho del uso que se haga y sólo la experiencia con nuestro tipo de instalación y uso del almacenamiento nos dirá lo que tenemos que usar en cuanto a memoria.
De todos modos la documentación oficial nos dice algo tan fácil como que cuanta más RAM mejor.
CPU
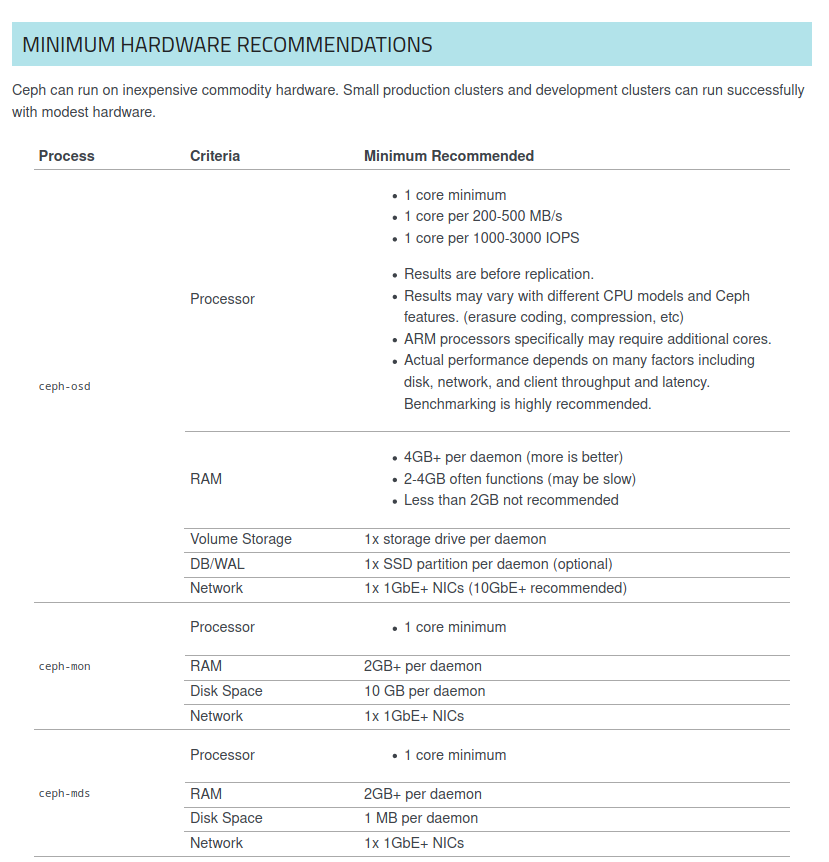
La documentación oficial de Ceph nos indica que las siguientes recomendaciones mínimas por OSD:
- 1 core mínimo
- 1 core por cada 200-500 MB/s
- 1 core por cada 1000-3000 IOPS
Tenemos que tener en cuenta que Ceph es un SDS (Software Defined Storage), así que la latencia también va a verse afectada por la CPU.
Red
En Ceph tener una red de 10G es muy recomendable, con una red de 1G funcionará, pero en el peor de los casos debido al aumento de latencia algunos OSDs podrían darnos timeout causando inestabilidades en el cluster, así que si no tenéis 10G Ceph no es para vosotros.
El RTT para un paquete de 4k en una red de 10G suele ser de unos 90us, mientras que en una red de 1G es de 1ms.
Recuperación ante fallos
Las tecnologías de almacenamiento tradicionales suponen una fiabilidad del hardware del 100%, por eso controladoras redundantes, bandejas redundantes, etc…
En Ceph los fallos de hardware están previstos y la forma de enfrentarse a ellos.
Obviamente con clusters más pequeños más impacto habrá ante fallos y cuanto más grandes menos simplemente porque el porcentaje de información afectada será menor si hay muchos más nodos.
Implementación mínima
La implementación mínima tendrá en las variables del pool en size=3 y en min_size=2.
- size: número de réplicas para objetos en el pool.
- min_size: número de réplicas mínimo requerido por i/o.
BlueStore
Cuando estuvimos instalando Ceph con proxmox se montaron los OSDs con tipo BlueStore, de hecho si vais en vuestro proxmox a un nodo, luego a Ceph y finalmente a OSD es muy probable que en la columna OSD Type veáis que todos los OSDs son de tipo BlueStore y ninguno de tipo FileStore.
FileStore tenía entre otros problemas la escalabilidad o que necesitaba un interfaz para el sistema de ficheros, cosa que BlueStore no necesita. Estamos hablando de la versión de Ceph Luminous.
BlueStore es el tipo de almacenamiento de bloques utilizado por Ceph. En Ceph los datos tienen asociados unos metadatos y es muy importante que tanto los datos como los metadatos puedan ser actualizados en una única transacción. Los datos serán los datos en si y los metadatos serán gestionados por RocksDB.
Foto de Tiger Lily en Pexels